یادگیری ماشین چیست؟
یادگیری ماشینی زیرشاخهای از هوش مصنوعی (AI) است که شامل توسعه الگوریتمها و مدلهایی است که رایانهها را قادر میسازد از دادهها یاد بگیرند و عملکرد را در یک کار خاص بدون برنامهریزی صریح بهبود بخشند. این روشی برای تجزیه و تحلیل داده است که ساخت مدل تحلیلی را خودکار می کند و به رایانه ها امکان می دهد الگوها را شناسایی کرده و بر اساس ورودی داده ها تصمیم بگیرند. یادگیری ماشین به ویژه برای مجموعه داده های پیچیده و در مقیاس بزرگ مفید است، جایی که روش های آماری سنتی ممکن است موثر نباشند و در کاربردهای مختلفی مانند تشخیص تصویر و گفتار، پردازش زبان طبیعی، سیستمهای توصیه و تحلیل پیشبینی استفاده میشود.
مدل های یادگیری ماشینی را می توان به سه نوع اصلی دسته بندی کرد:
در یادگیری نظارت شده، مدل بر روی داده های برچسب دار آموزش داده می شود، جایی که خروجی صحیح برای هر ورودی ارائه می شود.
در یادگیری بدون نظارت، مدل بر روی داده های بدون برچسب آموزش داده می شود، جایی که هدف یافتن الگوها یا گروه بندی ها در داده ها است.
در یادگیری تقویتی، مدل از طریق آزمون و خطا از طریق تعامل با محیط خود و دریافت بازخورد به صورت پاداش یا تنبیه یاد می گیرد.
یادگیری نظارت شده نوعی از یادگیری ماشینی است که در آن الگوریتم بر روی یک مجموعه داده برچسبگذاری شده آموزش داده میشود. داده ها از قبل با خروجی صحیح برچسب گذاری شده اند و الگوریتم سعی می کند یک تابع نقشه برداری را یاد بگیرد که بتواند خروجی را برای داده های ورودی جدید پیش بینی کند. یادگیری تحت نظارت به طور گسترده در برنامه های کاربردی مختلف مانند تشخیص تصویر، تشخیص گفتار و ترجمه زبان استفاده می شود. از سوی دیگر، یادگیری بدون نظارت نوعی از یادگیری ماشینی است که در آن الگوریتم بر روی یک مجموعه داده بدون برچسب آموزش داده می شود. هدف از یادگیری بدون نظارت، یافتن الگوها و روابط در داده ها بدون دانش قبلی از خروجی است. یادگیری بدون نظارت در برنامه هایی مانند خوشه بندی، کاهش ابعاد و تشخیص ناهنجاری استفاده می شود. درک تفاوت ها و کاربردهای این دو نوع یادگیری برای ساختن مدل های یادگیری ماشینی موثر ضروری است.

اهمیت داده ها
اهمیت داده ها را نمی توان در زمینه یادگیری ماشین نادیده گرفت. الگوریتم های یادگیری ماشینی فقط به اندازه داده هایی هستند که تغذیه می شوند. کیفیت و کمیت داده ها تأثیر مستقیمی بر دقت و اثربخشی مدل های یادگیری ماشین دارد. در واقع، موفقیت مدل های یادگیری ماشینی به در دسترس بودن مجموعه داده های مرتبط، قابل اعتماد و متنوع بستگی دارد. بدون دادههای با کیفیت خوب، مدلهای یادگیری ماشینی نمیتوانند در طول زمان یاد بگیرند، تطبیق دهند و بهبود یابند. بنابراین، سرمایهگذاری بر روی پردازش دادهها، پیشپردازش و پاکسازی بسیار مهم است تا اطمینان حاصل شود که دادههای مورد استفاده در یادگیری ماشین دقیق، کامل و عاری از خطا و سوگیری هستند. علاوه بر این، حفظ حریم خصوصی و امنیت داده ها نیز باید هنگام جمع آوری، ذخیره و استفاده از داده ها در برنامه های یادگیری ماشین در نظر گرفته شود.
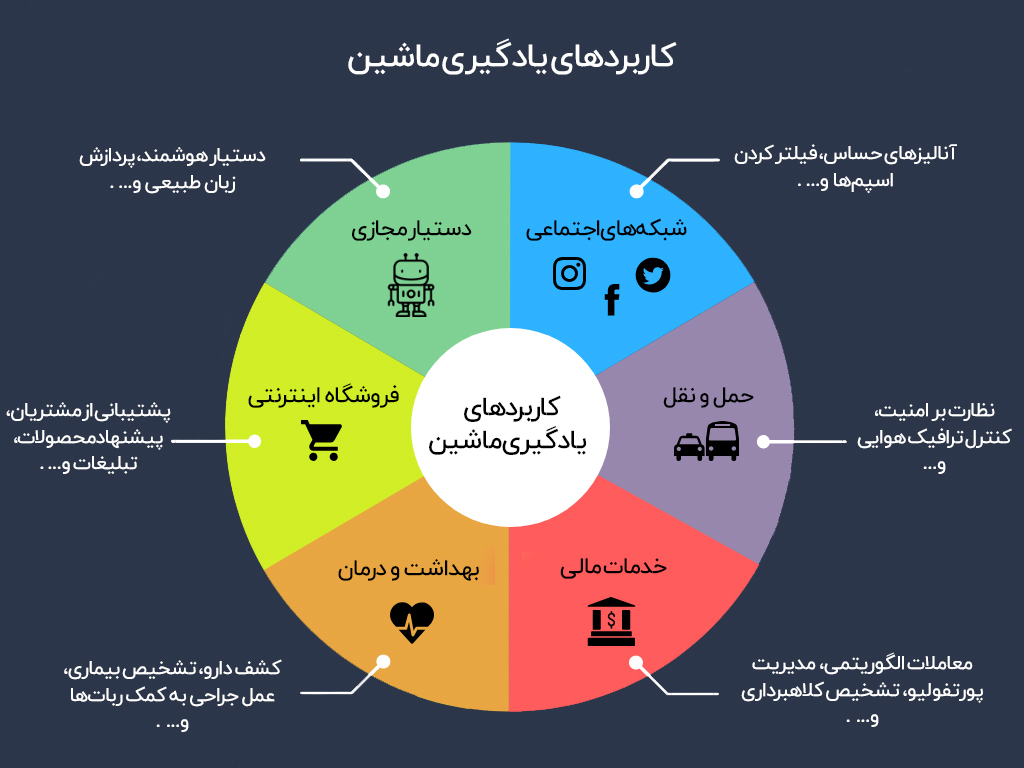
پیشرفت ها و برنامه های کاربردی آینده
یادگیری ماشینی در سالهای اخیر پیشرفتهای چشمگیری داشته است که منجر به پیشرفتهای متعددی در زمینههایی مانند پردازش زبان طبیعی، بینایی کامپیوتر و روباتیک شده است. یکی از امیدوارکنندهترین زمینههایی که یادگیری ماشینی در آن پیشرفت میکند، مراقبتهای بهداشتی است، جایی که از آن برای توسعه ابزارهای تشخیصی دقیقتر و برنامههای درمانی شخصیشده استفاده میشود. علاوه بر این، یادگیری ماشین در امور مالی برای شناسایی تقلب و بهبود مدیریت ریسک، و همچنین در حملونقل برای بهینهسازی مسیرها و کاهش تراکم ترافیک استفاده میشود. با نگاهی به آینده، انتظار میرود که یادگیری ماشین نقش حیاتی در توسعه وسایل نقلیه خودران و شهرهای هوشمند، در میان سایر کاربردها، ایفا کند. همانطور که تکنولوژی به تکامل خود ادامه می دهد، واضح است که یادگیری ماشینی به کمک قابل توجهی در صنایع مختلف ادامه خواهد داد و شیوه زندگی و کار ما را متحول خواهد کرد.
برخی از زمینه هایی که یادگیری ماشین در آن ها کاربرد دارد:
روانشناسی
فلسفه
تئوری اطلاعات
آمار و احتمالات
تئوری کنترل
کنترل روبات
داده کاوی
تشخیص گفتار
شناسائی متن
پردازش داده های اینترنتی
بازی های کامپیوتری